turnaround를 줄이고 싶으면 SJF/STCF 쪽, response time을 좋게 하고 싶으면 RR 쪽, 현실 시스템에선 interactive와 CPU-bound를 같이 처리해야 하므로 MLFQ 쪽, 비율대로 공정하게 나누고 싶으면 proportional share/lottery/stride 쪽으로…
mechanism: 어떻게 전환할 것인가
policy: 언제, 누구로 전환할 것인가
workload
작업의 집합. 각 작업의 도착 시간(arrival time), 실행 시간(run time) 같은 정보가 workload를 이룬다.
scheduler
언제 어떤 job을 돌릴지 결정하는 로직
metric
스케줄링 품질을 재는 기준
Scheduling Performance Metrics
Turnaround time
완료까지 걸린 시간: T_{turnaround} = T_{completion} - T_{arrival}
예를 들어 어떤 작업이 0
초에 도착해서 30
초에 끝났다면 turnaround time은 30
이다.
배치 작업처럼 “전체 완료가 빨라야” 하는 경우 중요하다.
Response time
처음 CPU를 받기까지 걸린 시간: T_{response} = T_{firstrun} - T_{arrival}
예를 들어 사용자가 터미널에 명령을 쳤는데 3
초 뒤에야 첫 출력이 뜨면 response time은 3
초다.
인터랙티브 시스템에서는 이 값이 매우 중요하다. “전체 완료는 좀 늦어도 일단 반응은 빨라야” 사용자 입장에서 좋기 때문이다.
Waiting time
Ready queue에서 기다린 시간이다.
CPU는 아직 못 받고 대기열에 서 있던 시간이라고 생각하면 된다.
Throughput
단위 시간당 얼마나 많은 작업을 완료했는가를 나타낸다.
예를 들어 1초에 100개의 job을 끝내면 throughput이 높은 것이다.
Resource utilization
CPU, 디스크 같은 비싼 자원을 얼마나 놀리지 않고 잘 쓰는가를 본다.
Overhead / Fairness
context switch가 너무 많으면 overhead가 커진다.
특정 프로세스만 계속 돌면 fairness가 나빠진다.
따라서 scheduler는 오버헤드는 줄이고 fairness는 높이는 방향으로 설계되어야 한다.
Workload Assumptions
처음에는 분석을 쉽게 하려고 다음과 같은 단순한 가정을 둔다.
각 job의 실행 시간은 같다.
모든 job은 동시에 도착한다.
한 번 시작하면 끝날 때까지 계속 실행된다.
모든 job은 CPU만 사용하고 I/O는 없다.
각 job의 실행 시간을 미리 안다.
이 단계에서는 주로 turnaround time을 중심으로 본다.
FIFO
FIFO = First-Come, First-Served
먼저 도착한 job을 먼저 실행한다.
non-preemptive 방식이다.
starvation은 없지만, convoy effect 문제가 있다.
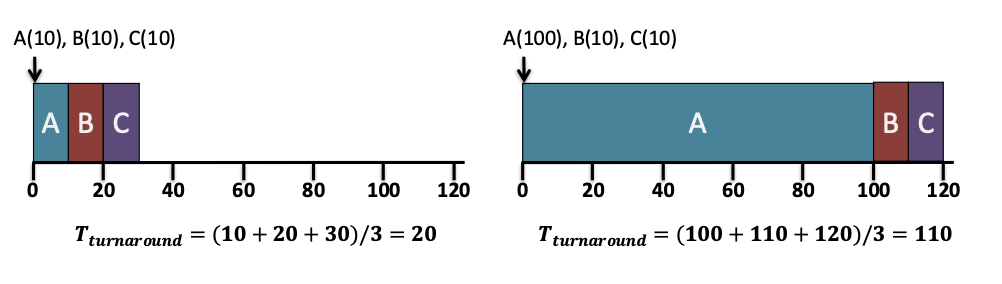
예시 1
A(10), B(10), C(10)
이 동시에 도착.
실행 순서: A \rightarrow B \rightarrow C
완료 시간: A = 10
, B = 20
, C = 30
평균 turnaround time: \frac{10 + 20 + 30}{3} = 20
예시 2: convoy effect
A(100), B(10), C(10)
이 동시에 도착하고 A
가 먼저 실행됨.
실행 순서: A \rightarrow B \rightarrow C
완료 시간: A = 100
, B = 110
, C = 120
평균 turnaround time: \frac{100 + 110 + 120}{3} = 110
짧은 작업 B, C
가 긴 작업 A
뒤에서 오래 기다리게 된다.
이게 convoy effect다.
SJF
SJF = Shortest Job First
실행 시간이 가장 짧은 job부터 먼저 실행한다.
non-preemptive 방식이다.
주어진 가정 아래에서는 평균 turnaround time이 최적이다.
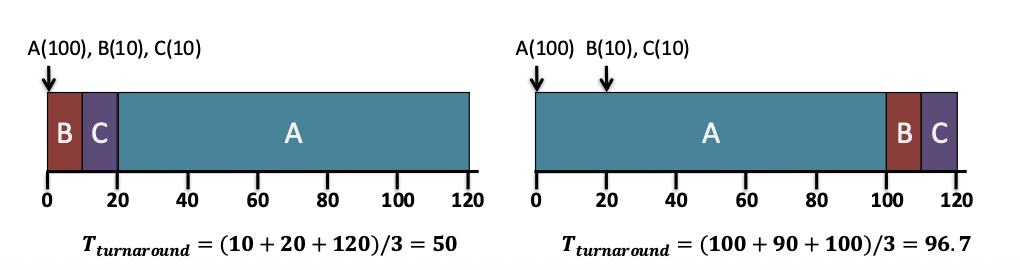
예시
A(100), B(10), C(10)
실행 순서: B \rightarrow C \rightarrow A
완료 시간: B = 10
, C = 20
, A = 120
평균 turnaround time: \frac{10 + 20 + 120}{3} = 50
FIFO의 110
보다 훨씬 좋아진다.
짧은 작업을 먼저 끝내면 평균 완료 시간이 크게 줄어든다.
한계
job의 실행 시간을 현실에서는 미리 알기 어렵다.
job이 동시에 도착하지 않으면 항상 최적이 아니다.
긴 작업이 계속 밀릴 수 있어서 starvation 가능성이 있다.
Preemptive Scheduling
non-preemptive scheduling에서는 현재 job이
I/O를 하거나
yield() 하거나
exit 해야만 다른 job이 CPU를 받을 수 있다.
preemptive scheduling에서는 scheduler가 현재 프로세스를 강제로 중단하고 context switch를 일으킬 수 있다.
STCF
STCF = Shortest Time-to-Completion First
SJF의 preemptive 버전이다.
핵심은 남은 실행 시간이 가장 짧은 job을 계속 선택하는 것이다.
규칙
현재 실행 중인 job보다 더 짧은 새 job이 도착하면, 현재 job을 preempt하고 새 job을 먼저 실행한다.
예시
A(100)
이 먼저 시작
나중에 B(10), C(10)
도착
SJF에서는 이미 A
가 시작했으므로 끝까지 가서 평균 turnaround가 나빠질 수 있다.
STCF에서는 B, C
가 들어오자마자 A
를 중단하고 먼저 처리한다.
평균 turnaround time: \frac{120 + 10 + 20}{3} = 50
짧은 작업을 빨리 끝내서 평균 완료 시간을 크게 줄일 수 있다.
RR
RR = Round Robin
run queue를 원형 FIFO처럼 보고, 각 job에 time slice(quantum) 를 조금씩 나눠 준다.
preemptive 방식이다.
starvation은 없다.
response time을 개선하는 데 강하다.
quantum
너무 짧으면 context switch overhead가 커진다.
너무 길면 responsiveness가 나빠진다.
보통 10 \sim 100ms
정도를 쓴다.
예시
A(30), B(30), C(30)
quantum = 10
SJF일 때
실행 순서: A \rightarrow B \rightarrow C
평균 turnaround time: \frac{30 + 60 + 90}{3} = 60
평균 response time: \frac{0 + 30 + 60}{3} = 30
RR일 때
실행 순서: A \rightarrow B \rightarrow C \rightarrow A \rightarrow B \rightarrow C \rightarrow A \rightarrow B \rightarrow C
평균 turnaround time: \frac{70 + 80 + 90}{3} = 80
평균 response time: \frac{0 + 10 + 20}{3} = 10
RR은 turnaround는 나빠질 수 있지만, response time은 훨씬 좋아진다.
그래서 time-sharing 환경에 적합하다.
(Static) Priority Scheduling
각 job에 고정 priority를 준다.
priority가 높은 job을 먼저 실행한다.
같은 priority끼리는 RR이나 FIFO를 쓸 수 있다.
preemptive일 수도 있고 non-preemptive일 수도 있다.
한계
높은 priority job이 계속 들어오면 낮은 priority job은 영원히 실행되지 못할 수 있다.
즉 starvation 문제가 생긴다.
Incorporating I/O
현실의 workload는 CPU만 쓰지 않는다.
어떤 job은 짧게 CPU를 쓰고 곧바로 I/O를 기다리고,
어떤 job은 CPU를 길게 점유한다.
따라서 scheduler는 I/O를 고려해야 한다. 슬라이드는 이를 I/O-aware scheduling이라고 설명한다.
핵심 아이디어
computation과 I/O를 겹쳐서 자원 활용도를 높인다.
각 CPU burst를 하나의 독립적인 job처럼 취급한다.
예시
A
: interactive job
B
: CPU-intensive job
A
가 read()를 호출하고 디스크를 기다리는 동안 CPU를 놀리지 않고 B
를 실행시키면 전체 자원 활용도가 올라간다.
즉 좋은 scheduler는 CPU와 disk를 겹쳐서 사용하려고 한다.
xv6 CPU Scheduler
xv6는 기본적으로 Round Robin scheduling을 사용한다.
매 timer IRQ마다 process에게 yield를 강제한다.
yield()
현재 프로세스를 RUNNABLE 상태로 바꾸고 sched()를 호출한다.
즉 “나는 CPU를 내놓고 ready queue로 돌아간다"는 뜻이다.
scheduler()
CPU별로 무한 루프를 돌면서 process table을 순회한다.
RUNNABLE인 프로세스를 찾으면 그 프로세스를 RUNNING 상태로 바꾸고 실행시킨다.
다시 돌아오면 또 다음 runnable process를 찾는다.
trap에서 timer IRQ 처리
timer interrupt가 오면 현재 process가 RUNNING 상태일 때 yield()를 호출한다.
이걸 통해 RR이 구현된다.
Towards a General CPU Scheduler
목표
turnaround time 최적화
interactive job의 response time 최소화
문제
현실에서는 workload를 미리 알 수 없다.
job의 실행 시간을 사전에 정확히 아는 경우가 드물다.
따라서 scheduler는 과거 행동을 보고 미래를 예측해야 한다.
MLFQ
MLFQ = Multi-Level Feedback Queue
priority level마다 여러 queue를 두고,
queue 사이에서는 priority scheduling
같은 queue 안에서는 RR을 사용한다.
핵심은 priority가 고정이 아니라, 관찰된 행동에 따라 변한다는 점이다.
기본 규칙
Rule 1: Priority(A) > Priority(B)
이면 A
가 실행된다.
Rule 2: Priority(A) = Priority(B)
이면 A, B
는 RR로 실행된다.
Changing Priority
전형적인 workload는 보통 두 종류가 섞여 있다.
interactive jobs
짧게 실행되고 빠른 response time이 중요하다.
CPU-intensive jobs
CPU를 오래 사용하고 response time은 덜 중요하다.
Attempt #1 규칙
Rule 3: 새 job은 가장 높은 priority queue에 들어간다.
Rule 4a: time slice를 전부 다 쓰면 priority를 한 단계 낮춘다.
Rule 4b: time slice를 다 쓰기 전에 CPU를 내놓으면 같은 priority를 유지한다.
직관
처음엔 모든 job을 interactive하다고 가정하고 좋은 대우를 해 준다.
CPU를 오래 계속 쓰는 job은 “CPU-bound겠구나” 하고 점점 아래 queue로 내린다.
짧게 쓰고 자주 I/O 하러 가는 job은 높은 priority를 유지한다.
Scheduling Under Rules 1-4
long-running job은 점점 아래 queue로 밀린다.
short-running, interactive job은 위 queue에 남아서 빠르게 반응한다.
그래서 MLFQ는 인터랙티브 workload에 유리하다.
Priority Boost
Attempt #1에는 문제가 있다.
long-running job이 starvation 될 수 있다.
malicious user가 time slice 끝나기 직전에 CPU를 내놓으며 scheduler를 속일 수 있다.
프로그램의 성격이 시간에 따라 변할 수도 있다.
해결 규칙
Rule 5: 일정 시간 S
가 지나면 시스템의 모든 job을 topmost queue로 올린다.
효과
아래 queue에 오래 있던 job도 다시 CPU를 받을 기회를 얻는다.
starvation을 완화한다.
Better Accounting
Rule 4a/4b만 쓰면 process가 scheduler를 속일 수 있다.
그래서 슬라이드는 Rule 4를 더 정밀하게 바꾼다.
새 Rule 4
어떤 level에서 할당된 총 CPU allotment를 다 쓰면,
몇 번에 나눠 썼는지와 관계없이
priority를 낮춘다.
의미
“한 번에 quantum을 다 썼는가?“가 아니라,
“그 level에서 누적해서 얼마나 CPU를 썼는가?“를 본다.
그래서 잘게 나눠 쓰면서 priority를 유지하려는 꼼수를 막을 수 있다.
MLFQ Final Rules
priority가 높은 job이 먼저 실행된다.
같은 priority면 RR을 사용한다.
새 job은 가장 높은 priority에서 시작한다.
한 level에서 allotted CPU time을 다 쓰면 아래 queue로 내려간다.
일정 시간마다 모든 job을 top queue로 boost한다.
Beauty of MLFQ
각 process의 CPU usage를 미리 알 필요가 없다.
scheduler가 실행 패턴을 관찰하면서 추정해 나간다.
UNIX Scheduler
실제 UNIX 계열 scheduler는 대체로 preemptive priority scheduling + time slice 기반이다.
process priority는 동적으로 변한다.
interactive process를 CPU-bound process보다 더 우대한다.
aging을 통해 starvation을 줄인다.
오래 기다리면 priority를 올리고
CPU를 많이 쓰면 priority를 내린다.
Proportional Share Scheduling
각 process에 weight를 주고 CPU를 그 비율대로 나눈다.
관점은 “누가 먼저 실행될까?“보다 “누가 CPU를 몇 퍼센트 가져야 할까?“에 가깝다.
예시
A: 25\%
B: 12.5\%
C: 50\%
D: 12.5\%
장기적으로 CPU 사용량도 이 비율에 가까워져야 한다.
Lottery Scheduling
proportional share를 구현하는 한 가지 방법이다.
각 process는 ticket을 가진다.
ticket 수가 많을수록 CPU를 받을 확률이 높다.
random number generator로 당첨 ticket을 뽑아 그 process를 실행한다.
예시
A: 50
tickets
B: 30
tickets
C: 20
tickets
장기적으로 CPU 비율은 대략 A: 50\%
, B: 30\%
, C: 20\%
에 가까워진다.
Stride Scheduling
lottery scheduling의 deterministic 버전이다.
stride는 ticket 수에 반비례한다.
pass value가 가장 작은 process를 선택하고, 그 process의 pass에 자기 stride를 더한다.
아이디어: stride \propto \frac{1}{tickets}
ticket이 많을수록 stride가 작다.
stride가 작을수록 pass가 천천히 증가하므로 더 자주 선택된다.
예시
\tau_1
: tickets = 3
, stride = 2
\tau_2
: tickets = 2
, stride = 3
\tau_3
: tickets = 1
, stride = 6
매번 pass가 가장 작은 task를 골라 실행한다.
실행한 task의 pass에 stride를 더한다.
그러면 장기적으로 실행 비율이 ticket 비율에 맞춰진다.
Summary
배치 작업 중심
FIFO: 단순하지만 convoy effect
SJF: 평균 turnaround 최적
STCF: SJF의 preemptive 버전
인터랙티브 작업 중심
RR: response time 개선
static priority: 중요도 반영 가능하지만 starvation 가능
현실적 scheduler
I/O-aware scheduling 필요
xv6는 RR 기반
일반적인 현대 시스템은 workload를 모르므로 관찰 기반 scheduler가 필요
대표적으로 MLFQ가 있다.
공정한 비율 분배
proportional share
lottery scheduling
stride scheduling
한 줄 요약
turnaround를 줄이고 싶으면 SJF/STCF 쪽
response time을 좋게 하고 싶으면 RR 쪽
interactive와 CPU-bound를 함께 다루려면 MLFQ 쪽
CPU를 비율대로 공정하게 나누고 싶으면 proportional share / lottery / stride 쪽으로 간다.